

What I cannot create, I do not understand. – Richard Feynman
I do a lot of video chat for work. If it’s not a one on one, it’s pair programming. If it’s not pair programming, it’s a client meeting. I use a lot of Skype and Hangouts.
Sometimes they don’t work for unclear reasons. Sometimes file transfers fail. Sometimes screenshare breaks, or when it’s active you don’t get webcam, too. Or the connection lags or drops even though everything is running fast.
Every time I experience such a failure, I get really angry and think, “I could do this better!” But I never quite got angry enough… until now. I guess the weight of years of frustration finally got to me.
I wrote my own (prototype) video conferencing app. It turned out pretty well. And that’s what these posts are about.
Conventions & Caveats
We will be referencing a 640×480 24 bit color 24fps video stream throughout this series of posts. We will spell out bits vs bytes in most cases to avoid confusion, and when abbreviating will use Mb (lowercase) for bits and MB (uppercase) for bytes.
I am not a video codec professional and this is an experiment. MPEG-2, H.264, VP9 and other codecs represent the state of the art and are tremendously more complex and capable than what I will describe. I believe there are some good tradeoffs to my system (which I will discuss later), but it is by no means exhaustively optimized or tuned. There are plenty of obvious improvements I simply didn’t have time to explore in this side project.
Basic Update Algorithm
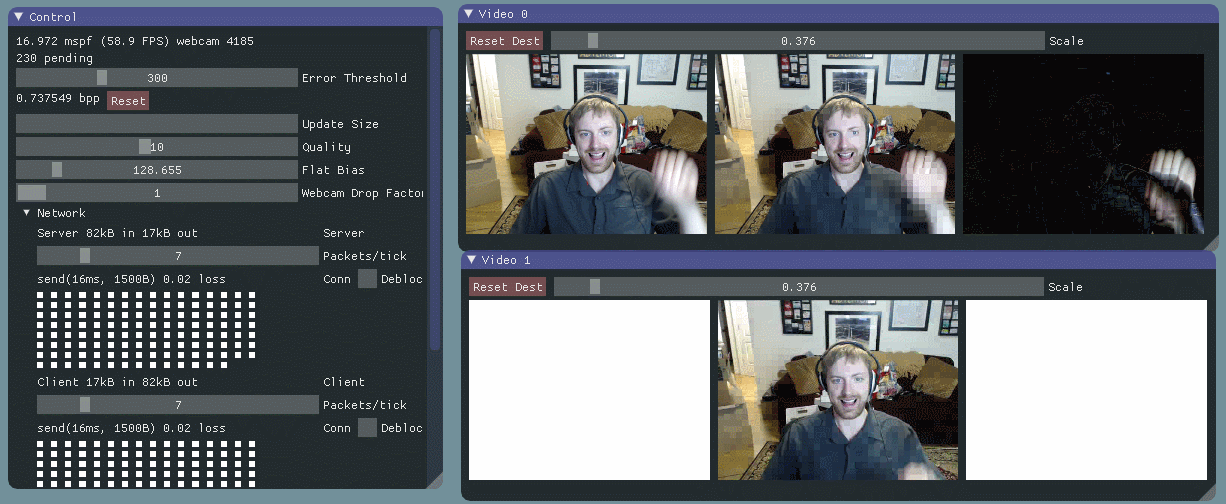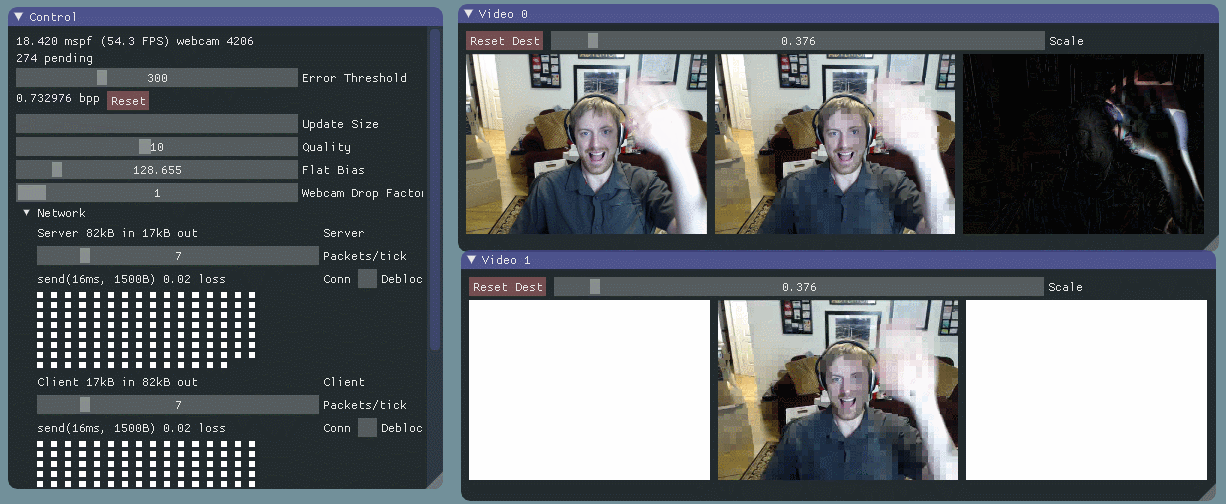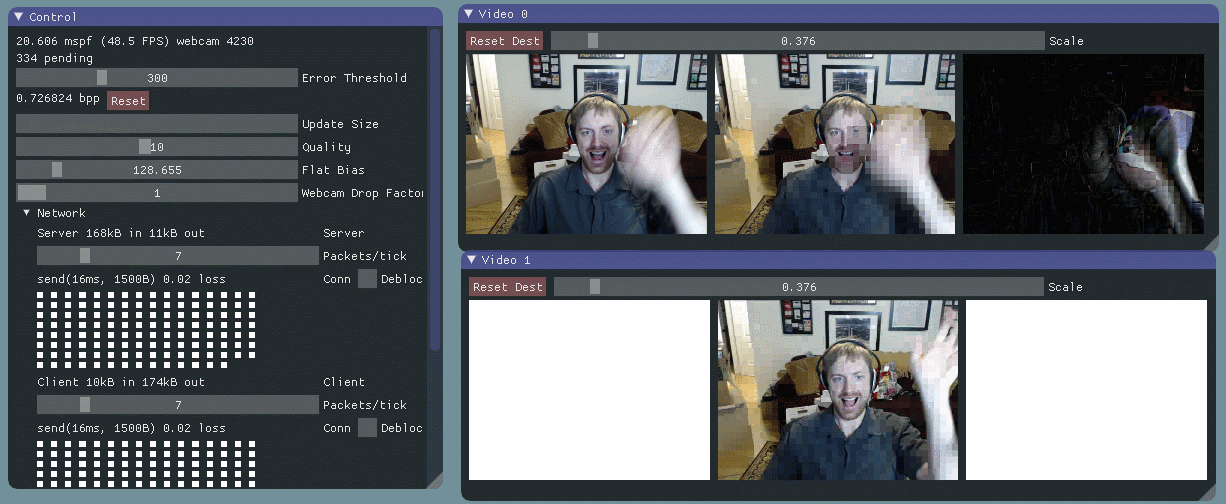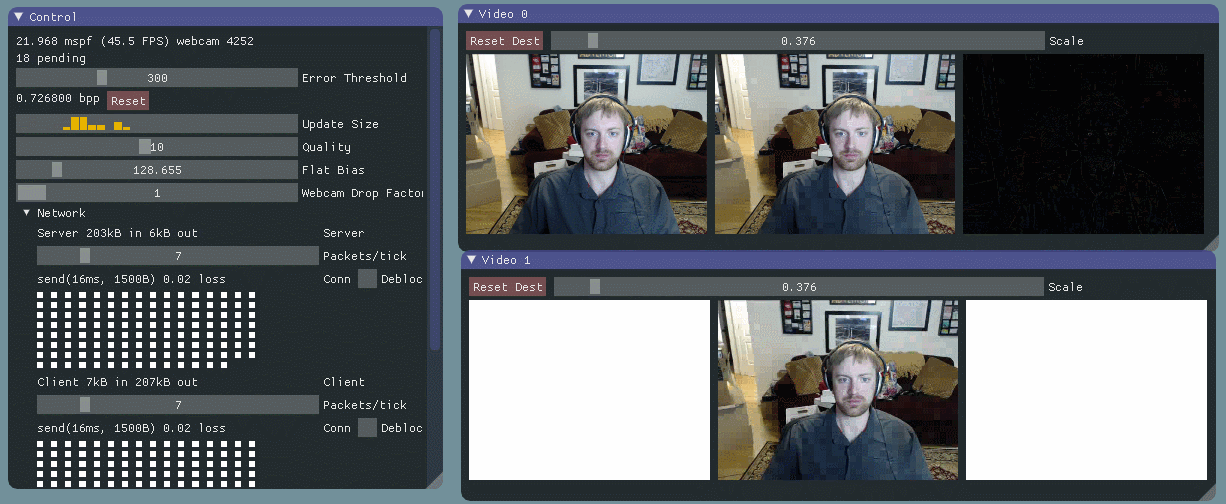
I started by prototyping a basic algorithm with no network communication – just moving data around in-process. I used dear imgui for the UI, and videoinput for the webcam capture. (I really enjoyed working with both for the first time.) I maintain two buffers, one holding the current frame from the webcam, and the other holding a model of what I’ve “sent” over the simulated network. I also show the per pixel error between the two.

I divide the images into 16px by 16px macroblocks, and calculate the error for each macroblock by taking the root mean square (RMS) of the client frame’s RGB values vs. the local frame’s RGB values for that region. I prioritize blocks with high error and transfer as many as I can every packet. I went with 16px macroblocks out of laziness – there’s lots of research and sample code based on that size.

As you can see, this is a self correcting system. Macroblocks with large errors – indicated by white – are constantly being “transmitted” and reduced to lower error – indicated by black. That is, it’s always trying to minimize the difference between what the client is seeing and the current state of the video feed. The rate at which the system converges on the new state is proportional to how fast we can transfer macroblocks. This allows us to scale to varying bandwidth situations, and it also strongly motivates us to have good compression.

As long as we have some feedback from the client, we can also handle data corrupted or dropped by the network. When we learn about lost data, we’ll update our model of the client state, and let the error correcting behavior handle it. More on that in a later post.
The main flaws with the system at this point are a) we aren’t networking anything yet and b) even if we did, it would require 221 megabits/second for 480p 30hz video sent as uncompressed RGB24. This means you’d have to have a well tuned 802.11n network at minimum – 802.11g would not be even close to fast enough. Peak LTE performance also would not come close to handling this much traffic.
Currently, macroblock updates cost us approximately 26 bits per pixel. We are a bit worse than just sending 8 bit RGB values because of overhead in the data protocol – we have to send macroblock positions, note the current compression settings, and so on.
Raw, zip & lzo
So we have an overall approach, but the bandwidth is way too high for any sort of real world use. We need to reduce our bandwidth by a factor of 30 for this system to be remotely plausible for use on the average 7 megabit broadband internet connection!
As MPEG-2, H.264, HEVC, VP9 and other codecs demonstrate, compressing video is definitely possible. 🙂 But those codecs are all complicated and often complex to integrate, modify or debug (said as someone maintaining a production system using ffmpeg). For instance, x264 is 100k lines of code without a lot of comments. Some codecs have substantial licensing fees. They also tend to have problems when data is lost during transmission. And many introduce substantial latency due to complex (but highly efficient) encoding processes.
A good rule for prototyping is to do the simplest thing first, then iterate. Add complexity as needed.
So I grabbed miniz and minilzo, and set it up so I could choose which compression technique to use on the macroblock data.
Since these are lossless compression algorithms, there was no change in image quality. However, we do see changes in macroblock update size. ZLib at level 9 achieved 23.8 bits per pixel. LZO achieved 28.9 bits per pixel. Not so good! Why are we getting such terrible results?
The biggest reason is that neither algorithm is particularly good at short blocks of data. Both have a “startup” phase where they can’t efficiently compress until a history is built up. Since every packet in our data stream must be self contained, we can’t rely on a shared history. This leads to a big efficiency loss. Even if we could have big blocks, noisy image data is hard to compress with this family of compressors – they are much better at repetitive, byte aligned data such as text.
We found basic run of the mill compressors to be a bust, but we did build the infrastructure to have compressed macroblocks, which is a vital step forward.
Next Time
Enough for prototyping today! We built a basic algorithm, got some basic performance parameters, and took our first baby steps with compression. We also set up an application framework that can display a complex UI and capture video.
Join us next time in Part 2 as we get our bandwidth down to a plausible range with some lossy compression!

11 responses to “Video Conference Part 1: These Things Suck”
[…] https://bengarney.com/2016/06/25/video-conference-part-1-these-things-suck/ “I wrote my own (prototype) video conferencing app. It turned out pretty well. And that’s what these posts are about.” […]
[…] Source: Video Conference Part 1: These Things Suck […]
Reblogged this on josephdung.
Reblogged this on PotentialMind.
[…] Video Conference Part 1: These Things Suck – Ben Garney – […]
[…] Source: Video Conference Part 1: These Things Suck – Ben Garney […]
Hi Ben,
Very interesting and inspiring read, thanks. May I ask you to elaborate on the following sentence:
> I maintain two buffers, one holding the current frame from the webcam, and the other holding a model of what I’ve “sent” over the simulated network.
The first buffer I get — nothing fancy, the actual current frame from source. But the second part of the sentence I did not grok — what _are_ you sending over the network? Since you mention “have sent”, can you tell a bit more what is this object that you actually model that is sent? Are you assembling macroblocks that consist of differences between frames? I hope I am clear with the question, appreciate if you explained it.
Hi Ben,
Very interesting and inspiring read, thanks. May I ask you to elaborate on the following sentence:
> I maintain two buffers, one holding the current frame from the webcam, and the other holding a model of what I’ve “sent” over the simulated network.
The first buffer I get — nothing fancy, the actual current frame from source. But the second part of the sentence I did not grok — what _are_ you sending over the network? Since you mention “have sent”, can you tell a bit more what is this object that you actually model that is sent? Are you assembling macroblocks that consist of differences between frames? I hope I am clear with the question, appreciate if you explained it.
Hi amn,
Thanks for asking.
I go into great detail about what I am sending in the later posts. Did you get to them? Post #3 in particular should have lots of details. But in a word, I prioritize macroblocks and try to fit as many of the most “important” ones in each packet I send out as I can. The specific format I use to send the macroblocks evolves throughout the next 3 posts in the series but eventually becomes fairy compact. I do not do residual encoding because I can’t guarantee the exact state of the client frame at the time I send the packet.
Cheers,
Ben
[…] Got fed up with Skype, wrote my own toy video chat codec/app, wrote articles about it. https://bengarney.com/2016/06/25/video-conference-part-1-these-things-suck/ […]
[…] Last time, I got angry at Skype and metaphorically flipped the table by starting to write my own video conference application. We got a skeleton of a chat app and a video codec up, only to find it had a ludicrous 221 megabit bandwidth requirement. We added some simple compression but didn’t get much return from our efforts. […]