

Last time we got up close and intimate with the core compression techniques used in the JPEG format, and applied them to our own situation for better compression. We got our data rates low enough that we have a shot at realtime video under ideal network conditions.
Now it’s time to actually send data over a network (or at least loopback)!
The Notify Protocol
We will use a UDP networking protocol derived from one used in the game engines I worked on at my first startup, GarageGames. The Torque networking protocol was state of the art when it was first used in the Tribes series from 1998 to 2001. It enabled realtime gameplay over a 56.6kb or worse modem, and represented a substantial improvement over the networking model used in Quake. You can read the original Tribes networking paper for a deeper discussion of the basic capabilities of the system.
For our purposes in this section, the essential feature of this networking model is the ability to be notified in realtime whether packets have been received by the other end of the connection, or dropped. We receive a callback in our code for each packet that was sent when its fate is known, along with a description of what was in the packet. This is the “notify” part of the protocol. For certain applications, this is a quantum leap relative to TCP, because it allows the application to respond to packet loss intelligently, rather than stalling the connection and resending old data.
You will recall back in the first post that we maintain a model of what we think the client is displaying, and prioritize macroblock updates based on the RMS error of our current local frame versus the client frame.
By using this protocol, we know when updates didn’t make it. If an update was lost, we revert the corresponding macroblock in the client frame to its state before that update was sent. Then the error metric will automatically reprioritize the macroblock for transmission. In the event that we have a newer update “in flight”, we ignore the failure – if the newer update makes it, the problem is resolved, and if it does not, it will cause a retransmission of the macroblock.

In other words, we only resend data when absolutely necessary, and only in the right order relative to other updates. This behavior makes the system robust under extremely high packet loss. You might not get full frames if on a bad connection, but you will see some changes, and eventually your view will become fully correct if a) the scene is static long enough or b) the network recovers.

The protocol, being designed for the high latency modem connections of the late 90s, handles latencies as high as 1000ms without an issue. Of course, the other end sees frames later, but they see them as soon as physically possible. There is no penalty beyond the time spent waiting on the data to get there.
We had to modify the protocol to support higher data rates, as it was originally optimized for connection speeds around 10kB/sec. With our changes, it can reliably transfer data at around 8 megabits/sec. Higher speeds are possible, but as you will see in the last post of this series, largely unnecessary.
Master & Arranged Connections
One benefit of using a game networking protocol is that it has robust support for NAT traversal. By running a light weight master server, we can track many thousands of clients on very modest hardware and make arranged connections that bypass most firewalls.
The NAT punching algorithm is simple but effective. When two peers request an arranged connection, the master server gives both a list of potential IPs/ports where the other peer might be found (typically where the master sees that peer’s traffic originating from, and the peer’s local IP/port), and part of a shared secret. Then the peers send punch packets to those IPs and ports.
For our prototype, we started with local network peer discovery (ie broadcast ping), then added support for entering an IP. Finally, we added automatic discovery of another random peer via the master server.
The master server connection can run at very low bandwidth, so a logical next step would be to do some authentication, track presence, and let you add contacts and initiate a conversation on demand. However, this is just a prototype and none of that is vital functionality!
Packet Math
One important thing to consider is all in packet overhead. It’s easy to get a false sense of confidence by focusing only on the compressed image data without considering the overhead of the full networking stack.
Our packet format header is about 94 bits or 12 bytes. UDP IPV4 header overhead is 28 bytes. Our packet overhead is therefore 40 bytes.
Reliable MTU size seems to be around 1200 bytes, leaving about 1160 bytes for data (3.3% overhead). This can/should be negotiated but is currently hard coded. On local network segments much larger MTUs are possible, and over the general Internet 1500 bytes often works.
The overhead per pixel will decrease as our compression gets better, but at a rough estimate, assuming 50 macroblocks per packet, we will see an overhead of 0.02bits/pixel.
A quick comparison to TCP suggests that on IPV4 we would see 4.3% overhead as opposed to 3.3% for our protocol. This is of course assuming an ideal connection. In the face of packet loss, TCP rapidly throttles down to try to find a data rate that lets the link behave well, losing lots of bandwidth. Our protocol accepts lost packets and rolls forward as best it can. So depending on the situation the difference will be a lot more than 1%.
Simulation Options
An important detail when building a robust system is being able to simulate network problems. If you don’t regularly test under bad conditions, your system rapidly becomes brittle. We have support for adding latency (ie delaying packet delivery) and randomly dropping packets (with a tunable frequency).
Next Steps
Here’s the best stream quality we can achieve in realtime over our network connection:
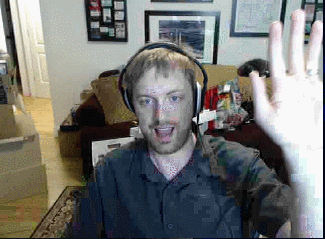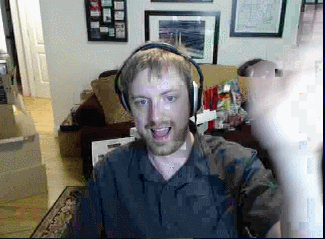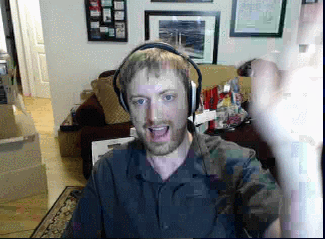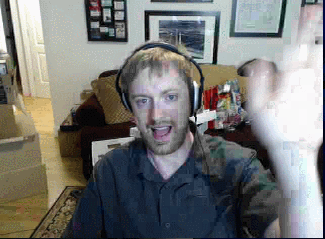
We’re running at a little over 8 bits per pixel or 7.3 megabits/sec. We can do a lot better – so now that we’re networking properly, we’ll go back for a final round of improvements in the next post (click to visit)!

2 responses to “Video Conference Part 3: Getting Online”
[…] Last post, we got our networking stack up and running, figured out how to work around firewalls, and saw how our codec performs over a real network link. This motivated us to revisit our compression schemes, which is what we’ll do in today’s post. […]
[…] Now that we can transfer little enough data to run the codec over a network, we should implement some networking and test it for real. And that’s exactly what we’ll do in Part 3! […]